The Exford English Dictionary
Where the bloody hell is Bielefeld?!
With Brexit looming over the fate of the EU, I thought: let’s get topical. Nah, not really. But the analysis, I lay before you today, is somewhat related to the UK. Inspired by a funny picture on the Internet with literal German translations of all tube stops in London, I wondered if the same is possible for cities in the UK and Germany. However, I wanted to use a mapping from each German city to a British one and vice versa based on the use of the city’s name in the natural language of each country. Every country has that one city which is bashed quite often in day-to-day language. Or sometimes they even deny the city’s whole existence but we will get to this later. My view on British cities is largely tainted by British panel shows. Glasgow has a weird accent, Northerners are no geniuses, people from Newcastle (Geordies) are a bit working-class and so on. My view on German cities is tainted as well because I am German. Köln is a concrete jungle, Berlin is full of Hipsters and only rich people live in München (I will use the German names for all German cities throughout the text). So, let’s find a way to directly map British city stereotypes to German city stereotypes.
Rise and shine!
Every good analysis starts with well-maintained data and data sources. Ohh wait, it does not! So, I went out with a light heart and a lot of swear words and scraped three things:
- the Wikipedia list of cities in the UK
- the Wikipedia list of cities in Germany
- geonames.org to find geolocations for all cities
This gives us a complete list of the 70 largest cities in the UK and Germany (140 in total) and all their locations in longitude and latitude.
For representing the cities, we need a concept to make the city names comparable. Over the last years, word embeddings have gained the recognition in doing so. I will not go into detail here but let’s just assume that any word embedding algorithm can transform a string (i.e. the city names) into a n-dimensional vector where similar words are represented by close-by vectors. This gives us direct comparability between cities because the cosine distance between two word vectors can be seen as an measure for similarity of word vectors.
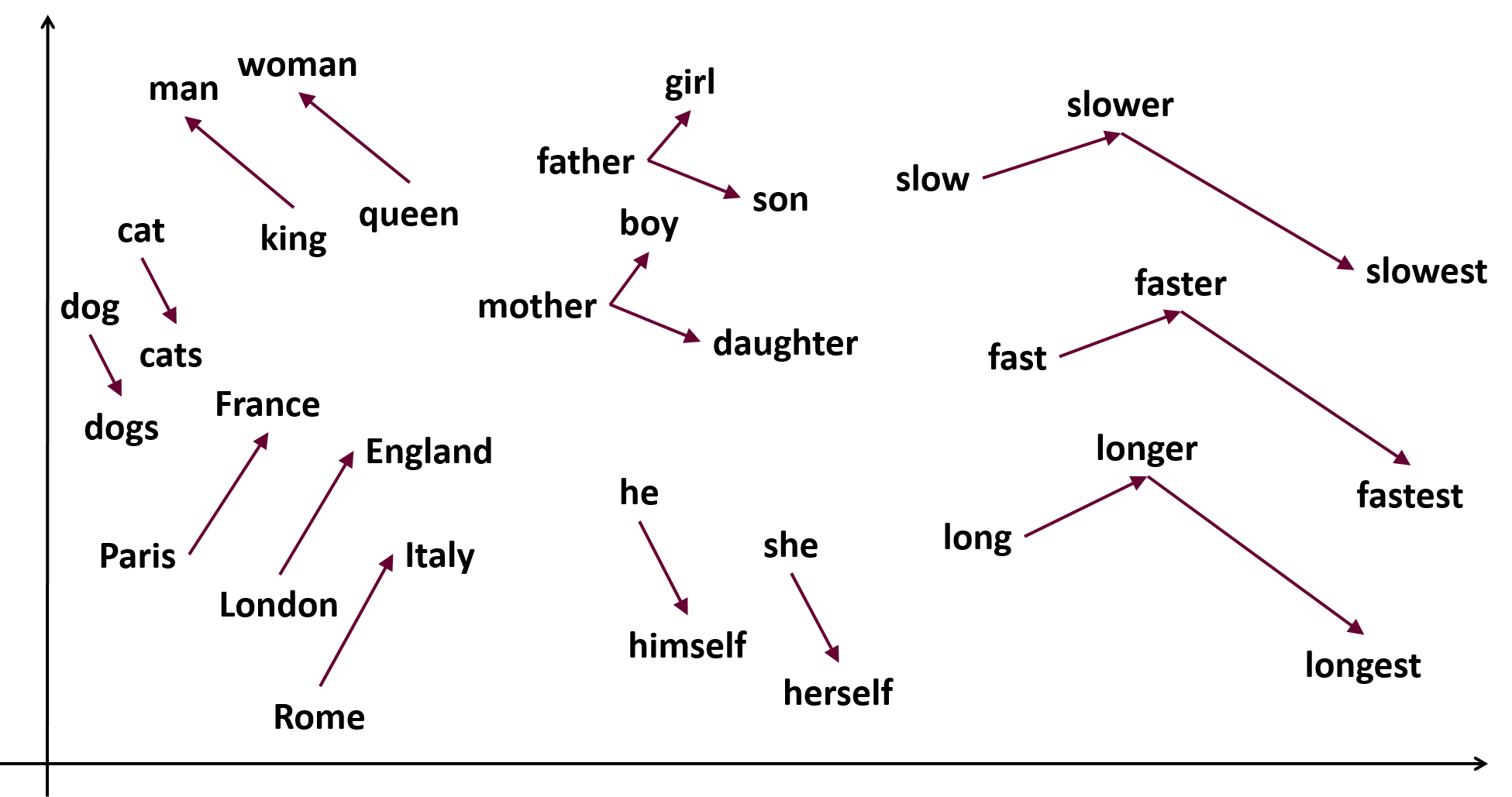
Image from https://samyzaf.com/
Since city names are just strings, we find all cities in the word vector space. I have chosen fastText for our analysis. More specific, I used the pretrained vectors trained on the English and German Wikipedia. If we just use these vectors there is still the problem of multiple languages. Because both vector spaces are trained independently, there is no alignment between the two. This means, I cannot compare vectors from the German vector space to the ones from the English one. Luckily, fastText also offers aligned word vectors where a post-processing step has aligned the vectors making them directly comparable.
Whereas the German Wikipedia is a closed environment, we have to take into account that the English Wikipedia also covers a lot of other English-speaking countries. So, the general perception of different cities might be shifted, especially if there is a city with the same name in the UK and the US. Additionally the Wikipedia is not really a source of stereotypes. It tries to be as neutral as possible. If anybody has some word vectors from something more vulgar, like Twitter or Youtube comments, I am happy to have a look at those as well.
Eenie Meenie Miney Mo
With the list of cities for both countries and their word vectors, we are now able to get their cosine similarity. The cosine similarity is 1 minus the cosine distance between two vectors.

birmingham dropped dresden for stuttgart. We now have a list of one-to-one mappings between British and German cities. No city gets mapped twice.
Don’t mention the war!
The mapping generates the following maps. Each city is replaced by its foreign counterpart.
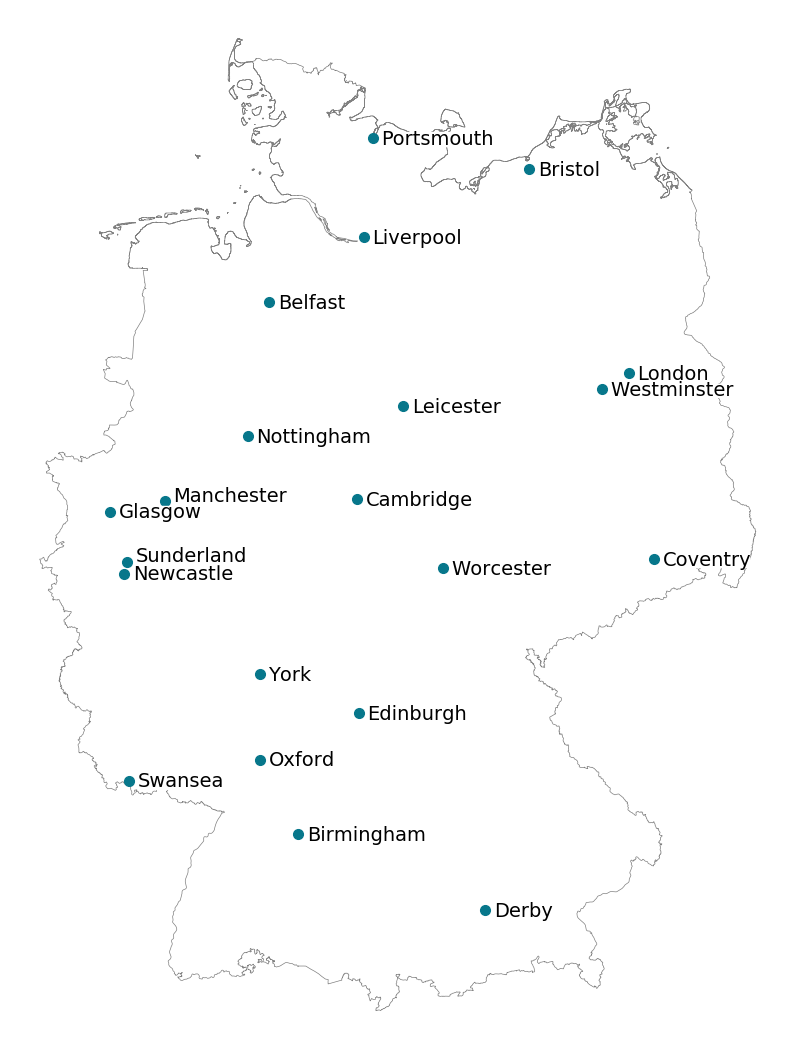
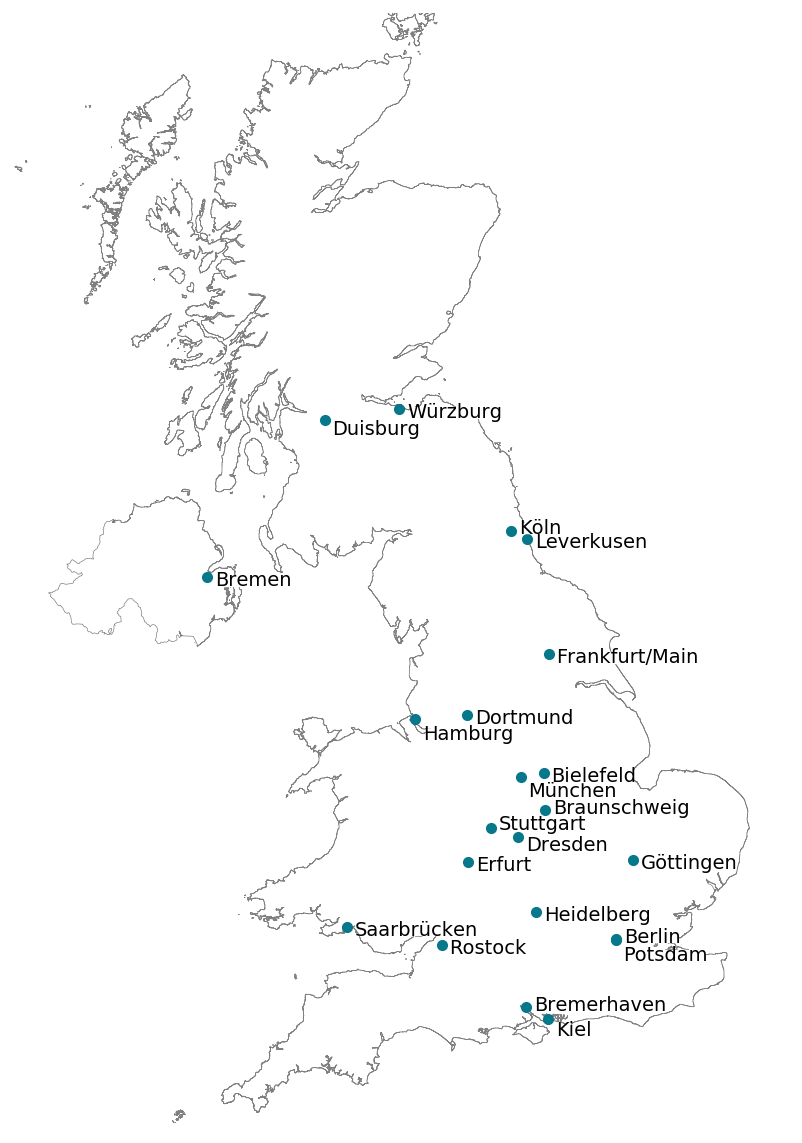 The comprehensive mapping can be found in the following table.
The comprehensive mapping can be found in the following table.
| City UK | City Germany | City UK | City Germany | City UK | City Germany | ||
|---|---|---|---|---|---|---|---|
| Aberdeen | Bonn | Edinburgh | Würzburg | Peterborough | Chemnitz | ||
| Albans | Pforzheim | Ely | Offenbach/Main | Plymouth | Düsseldorf | ||
| Armagh | Paderborn | Exeter | Münster | Portsmouth | Kiel | ||
| Asaph | Leipzig | Glasgow | Duisburg | Preston | Hamm | ||
| Bangor | Halle/Saale | Gloucester | Neuss | Ripon | Lübeck | ||
| Bath | Essen | Hereford | Wuppertal | Salford | Aachen | ||
| Belfast | Bremen | Hull | Krefeld | Salisbury | Kassel | ||
| Birmingham | Stuttgart | Inverness | Reutlingen | Sheffield | Nürnberg | ||
| Bradford | Solingen | Lancaster | Oldenburg | Southampton | Bremerhaven | ||
| Brighton/Hove | Herne | Leeds | Bochum | Stirling | Darmstadt | ||
| Bristol | Rostock | Leicester | Braunschweig | Stoke | Fürth | ||
| Cambridge | Göttingen | Lichfield | Magdeburg | Sunderland | Leverkusen | ||
| Canterbury | Mainz | Lincoln | Ulm | Swansea | Saarbrücken | ||
| Cardiff | Gelsenkirchen | Lisburn | Heilbronn | Swindon | Wolfsburg | ||
| Carlisle | Regensburg | Liverpool | Hamburg | Truro | Hannover | ||
| Chelmsford | Oberhausen | London | Berlin | Wakefield | Recklinghausen | ||
| Chester | Koblenz | Manchester | Dortmund | Wells | Wiesbaden | ||
| Chichester | Osnabrück | Newcastle | Köln | Westminster | Potsdam | ||
| Coventry | Dresden | Newport | Mannheim | Winchester | Ludwigshafen/Rhein | ||
| Davids | Hagen | Newry | Mülheim/Ruhr | Wolverhampton | Mönchengladbach | ||
| Derby | München | Norwich | Augsburg | Worcester | Erfurt | ||
| Derry | Bottrop | Nottingham | Bielefeld | York | Frankfurt/Main | ||
| Dundee | Ingolstadt | Oxford | Heidelberg | ||||
| Durham | Freiburg/Breisgau | Perth | Karlsruhe |
Let’s state the obvious. London and Berlin are similar because they are both capitals (and full of Hipsters). Similarly, Westminster and Potsdam are both cities near or within the capitals. Now, to the more interesting part. Surprisingly, Coventry and Dresden are very much intertwined in the use of language. But given their historic background that seems obvious as well. Also, most harbor cities have a harbor city counterpart, like Liverpool and Hamburg. Quite interestingly, the university cities of Oxford and Cambridge are mapped to two major German university cities Heidelberg and Göttingen.
Do you remember talking about stereotypes earlier? Funny how a city in Wales (Swansea) has a partner in Saarland (Saarbrücken). Both countries/states are mocked for … special interests in sheep. Additionally, a lot of places in the British industrial regions have mappings to the Ruhrpott, Germany’s largest industrial center in the west. All these cities are known for their working-class image. A good example is Manchester and Dortmund. Talking about negative images, funny accents and concrete go hand in hand as well. Both the pairs Newcastle/Köln and Sunderland/Leverkusen are pretty spot on for that matter. And lastly, according to our analysis, Nottingham does not exist because it is paired with Bielefeld, a city which famously does not exist.
Bye bye!
I cannot give a comprehensive list of interpretations because I do not know all language stereotypes in both languages. It is up to you to spot other connections. A lot comes from your media intake and personal experiences, I would guess. Now then, let me summarize what we achieved. We
- got information about British and German cities, like their similarity in language and their geolocation,
- got a comparability measurement between the cities and a ranking,
- got a visualization and a list of pairings,
- got an interpretation for some city pairs.
I hope you guys see this all in good fun. This work is not meant to be taken too seriously. But, the current situation between the UK and the EU gave me the motivation and inspiration to write down something that connects all of us: positive stereotypes. With that, the only thing left to say is: see ya GB. Until our paths might cross again. And therefore back to Bob Mortimer, Master of city hymns.
Built with Jupyter Notebooks, matplotlib, and Basemap.